|
I was able to publish a web version of NYC Restaurant Evaluator.
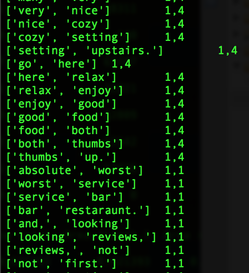
https://www.linkedin.com/pulse/nyc-restaurant-evaluator-tae-h-kim?trk=hp-feed-article-title-publish www.plot.nyc 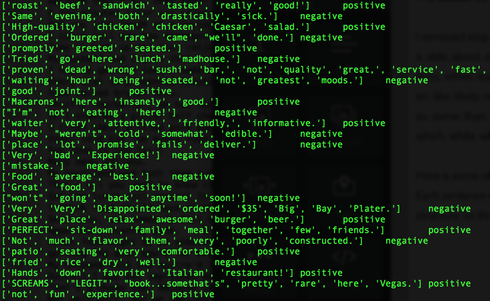 So, I bought an Amazon Echo. (Yes, I am an early adopter. lol). As of now, all this expensive gadget does for me is to play music. (The very first thing I say when I wake up in the morning is, "Alexa, play iHeartRadio."). I know some people finds Siri/Google Now as great interactive tools, and some never uses them. (I don't because the accuracy of search has not been yet satisfied me, but I am very certain I will use them more often. ) NLP is a hot topic, and there are tons of resources trying to improve human-computer interactions. (hey, we all grew up watching Knight Rider hoping someday we would own a KITT. ) As a personal project, I challenge myself to take a peak into Sentimental Analysis. I am not an expert by no means, but I am just curious to know and learn. UCI has Machine Learning Depository where it offers free data. (https://archive.ics.uci.edu/ml/datasets.html) The data that I download is Sentiment Labelled Sentences Data Set from this UCI Machine Learning Depository. (https://archive.ics.uci.edu/ml/datasets/Sentiment+Labelled+Sentences) I probably need to mention the donator of the data: Dimitrios Kotzias -> dkotzias '@' ics.uci.edu The dataset contains sentences gathered from imdb, amazon, and yelp which I will use as a training data. I removed stop-words from each sentences. (as of now, my stop-words are: a, able, about, across, after, all, almost, also, am, among, an, and, any, are, as, at, be, because, been, but, by, can, could, dear, did, do, does, either, else, ever, every, for, from, get, got, had, has, have, he, her, hers, him, his, how, however, i, if, in, into, is, it, its, just, least, let, like, likely, may, me, might, most, must, my, of, off, often, on, only, or, other, our, own, rather, said, say, says, she, should, since, so, some, than, that, the, their, them, then, there, these, they, this, tis, to, too, twas, us, wants, was, we, were, what, when, where, which, while, who, whom, why, will, with, would, yet, you, your). Here is some of the output from mapper. (I will use MapReduce). Each sentence will be printed out as a list of words and the value is whether it is positive or negative. (I am still working on how to structure key-value, so I am certain that this may change). Some makes sense with stop-words being deleted, but the very last output ['not', 'fun', 'experience.'] shows as positive. Hmm. So, I looked up, and the original sentence is "It was just not a fun experience" and has a positive rating. So, I guess it is time for data cleaning and validation! From skimming through the output, the length of the sentence does not seem to be a relevant measure, but I'll dig more into that. 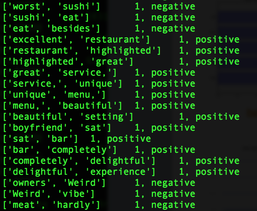 Some adjustment to my mapper. I paired 2 words of each sentences to figure out which 2 words occurs the most since I read "Pairs and Stripes" are common in Natural Language Processing. Maybe, I can apply association rule down the road.  Hmmm...little bit disappointing output of reducer. I wish the size of the training data was bigger since only 5 reviews contain "really good", 9 reviews contain "very good", and 11 reviews contain "not good" :( I guess it's time for different approach. 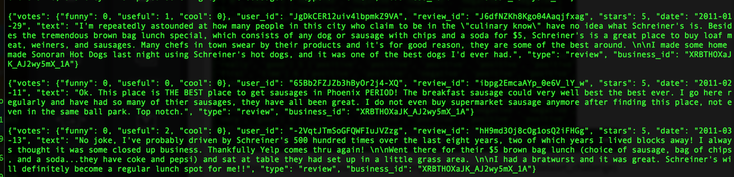 So I was able to get more data from Yelp via its Data Challenge (http://www.yelp.com/dataset_challenge). 1,569,264 rows of reviews! Yay! Not only the Yelp Challenge offers the dataset, but also it asks very informative questions. "Natural Language Processing (NLP): How well can you guess a review's rating from its text alone? What are the most common positive and negative words used in our reviews? Are Yelpers a sarcastic bunch? And what kinds of correlations do you see between tips and reviews: could you extract tips from reviews?"
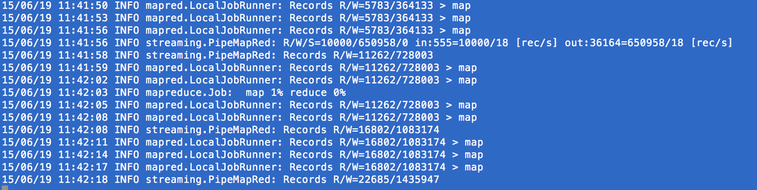 Ahhh...the wait time while hadoop MapReduce is running is so pleasant. It's time to meditate. I should've run this on HPC. Running this task on local after 10 minutes start to spill to hard drive. So, I made some changes, and ran both on local and HPC. Some of results are: (pair words, first number is the number of occurrence of these pairs, second number is the average) ['very', 'good'] 77114 3.87 ['first', 'time'] 60827 3.72 ['las', 'vegas'] 54478 3.93 ['customer', 'service'] 54360 3.08 ['pretty', 'good'] 53200 3.48 ['really', 'good'] 52922 3.95 ['come', 'back'] 50622 3.56 ['happy', 'hour'] 45753 3.79 ['great', 'place'] 40049 4.24 ['very', 'friendly'] 39055 4.19 ['ice', 'cream'] 37710 3.95 ['service', 'great'] 26867 4.24 ['mexican', 'food'] 17679 3.68 ['very', 'tasty'] 15269 4.01 ['quality', 'food'] 14360 3.57 ['prime', 'rib'] 13241 3.68 ['super', 'friendly'] 12987 4.45 ['saturday', 'night'] 12468 3.52 ['very', 'helpful'] 11603 4.28 ['always', 'good'] 11529 4.11 ['friendly', 'helpful'] 11285 4.28 ['mac', 'cheese'] 11181 3.78 ['chinese', 'food'] 10798 3.57 ['chips', 'salsa'] 9490 3.49 ['very', 'happy'] 9189 4.32 ['peanut', 'butter'] 6560 4.02 ['delicious', 'food'] 6405 4.46 ['very', 'disappointed'] 6086 1.83 ['absolutely', 'love'] 5995 4.57 ['24', 'hours'] 5897 3.64 ['never', 'disappointed'] 4974 4.52 ['very', 'pleased'] 4922 4.40 ['portion', 'size'] 4769 3.63 ['very', 'knowledgeable'] 4686 4.53 ['over', 'cooked'] 4417 2.48 ['always', 'fresh'] 4247 4.49 ['free', 'wifi'] 4096 3.91 -->Listen, restaurant owners. Free wifi will get you bonus point!! ['perfect', 'place'] 3705 4.31 ['waste', 'money'] 3167 1.72 .....List goes on and on Funny that this captured the fact that more time = worse the rating. ['few', 'minutes'] 10373 3.26 ['5', 'minutes'] 11669 2.91 ['10', 'minutes'] 18188 2.71 ['15', 'minutes'] 15919 2.69 ['20', 'minutes'] 14952 2.60 ['25', 'minutes'] 2799 2.43 ['40', 'minutes'] 3371 2.45 ['45', 'minutes'] 7742 2.60 ['over', 'hour'] 4179 2.40 Retention? ['first', 'time'] 60827 3.72 ['second', 'time'] 12280 3.32 ['3', 'times'] 7504 3.17 ['4', 'times'] 3103 3.29 ['5', 'times'] 2267 3.33 Stars ['2', 'stars'] 7071 2.31 ['3', 'stars'] 10977 3.07 ['4', 'stars'] 15022 3.68 ['5', 'stars'] 25409 4.17 We don't want to be disappointed! ['very', 'disappointed'] 6086 1.83 --> low ['never', 'disappointed'] 4974 4.52 -->high ["won't", 'disappointed'] 4776 4.58 -->higher To be continued
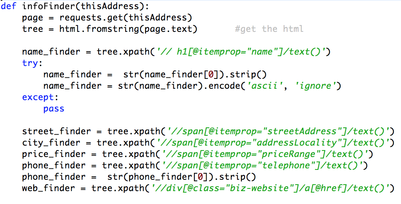
While searching for a restaurant on Yelp, I was curious to know what these letter grades of the Restaurant Inspection indicate. So, I started to search for the top restaurants in NYC on ZAGAT because they are supposed to be the cleanest. 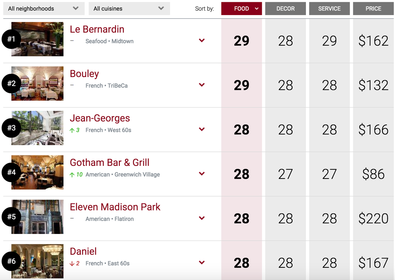 Pretty expensive and I am sure they offer very delicious dishes! (28-29 out of 30 must be good, especially if anyone is willing to pay that much!) So, I parsed Yelp links, and merged with the inspection data from The New York City Department of Health and Mental Hygiene.
I added the links of the top 10 restaurants on ZAGAT.
Please excuse the ugly user interface since it is only used by me. The purpose of this program is to keep a list of restaurants that I like, so that I can easily look up for phone numbers and addresses.
These violations were found from these top 10 restaurants: 1. Le Bernardin:
2. Bouley
3. Jean-Georges
4. Gotham Bar and Grill I could not parse data for this restaurant. Maybe, I could, but I did not attempt to. 5. Eleven Madison Park
6. Daniel I could not parse data again. If I see more of results like this, then maybe I should find a different way to merge the data. 7. Sushi Yasuda
8. Gramercy Tavern
9. Peter Luger Steak House
10. La Grenouille
This concludes my finding. Thanks for reading! *References: Top 100 data: https://www.zagat.com/best-restaurants/new-york Inspection data (Jan 2013 - Apr 2015) https://data.cityofnewyork.us/Health/DOHMH-New-York-City-Restaurant-Inspection-Results/xx67-kt59 * Please note that the most, if not all, of these violations may/should have been resolved by now. This is a personal project using publicly available data without any intention to harm or damage. Request for deletion:[email protected] |
AuthorTae Archives
November 2016
Categories |


 RSS Feed
RSS Feed
